
The LHCb collaboration is currently enhancing its unique system of data filtering, Real Time Analysis, by installing a 2nd set of Graphics Processing Units (GPUs) in the trigger system.
{kind=link}
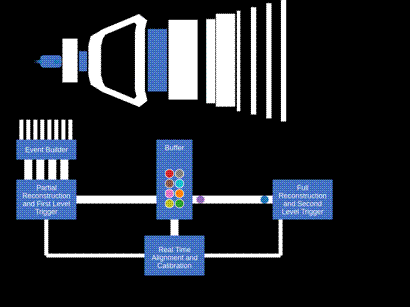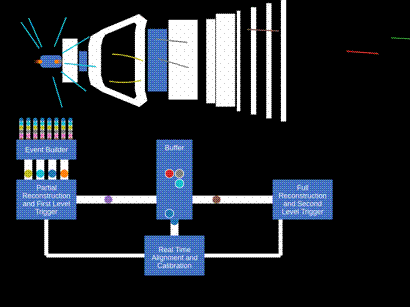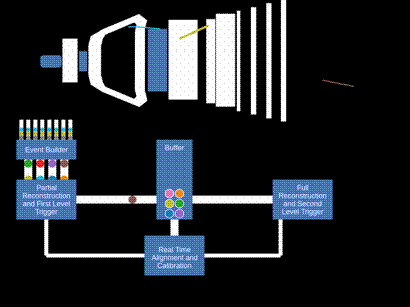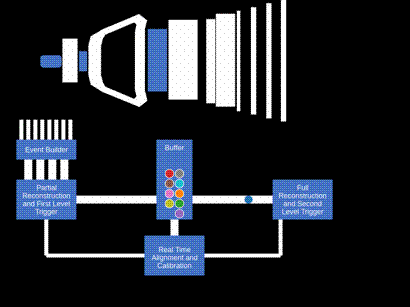
Current technology does not allow all LHC proton-proton collision data to be stored and analyzed. A fast event selection procedure, referred to as trigger, is therefore necessary, tailored to the scientific goals of each experiment. Thus the procedure of data-taking and analysis at hadron colliders traditionally has been performed in two steps. In the first one, called by physicists “online”, the data are recorded by the detector, read-out by fast electronics and processed by fast computer algorithms. At the end, a selected fraction of events is stored on disks and magnetic tapes. The stored events are then analyzed later in “offline analyses”. A crucial part of offline analysis is the determination of condition parameters depending on the data-taking period, for example alignment – the determination of the relative positions of the different sub-detectors and calibration – the precise determination of the relationship between the detector response and a physical quantity. The entire data sample is then reprocessed with this new set of parameters, before the final data analysis takes place. The whole process takes time and introduces a mismatch between the objects in the online and the offline analysis.
In order to avoid these features, the LHCb collaboration has made a revolutionary improvement to the data-taking and analysis process, called “Real-Time Analysis” (RTA). The final processing already takes place online, by performing the calibration and alignment processes automatically in the trigger system. The stored data are then immediately available offline for physics analyses.
In LHCb Run 2, the trigger was a combination of fast electronics (“hardware trigger”) and computer algorithms (“software trigger”). For Run 3 and beyond, the LHCb detector will run at a five times higher instantaneous luminosity than during Run 1 and 2. Consequently, the whole trigger system had to be changed radically: the hardware trigger has been removed and the whole detector is read out at the full LHC bunch-crossing rate of 40 MHz. This allows the full selection to be done in software, following the RTA paradigm.
{kind=link}
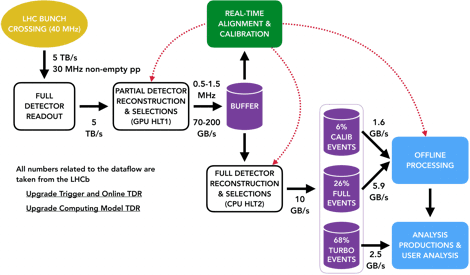
The heart of LHCb’s trigger is the data acquisition system, consisting of around 160 computer servers equipped with 480 custom electronic cards that receive and aggregate information from almost 1 million individual electronic channels from the full detector. This data, corresponding to a data rate of 5 Terabytes each second, is then passed on to the first stage of the trigger (HLT1).
In HLT1, data from multiple events is sent to GPUs located in the same servers that aggregate the detector data. This compact solution minimizes the amount of data to be moved around the network. Each GPU currently processes around 150 thousand events per second, keeping the full detector information for 3% of the most interesting events for further processing. This remaining data corresponds to 120 Gigabytes per second. At this stage, selected events are stored in a 40 Petabyte disk buffer. Buffering the data allows the relative positions of subdetectors to be determined with micrometer precision in real time. The performance of the detector for identifying different particle types is similarly calibrated with per mille accuracy at this stage. This real-time alignment and calibration ensures that LHCb retains optimal sensitivity for the many precision measurements that are the cornerstone of the collaboration’s physics programme. The presence of the disk buffer also allows the second trigger stage (HLT2) to be executed even when the LHC is not colliding protons, maximizing the utility of LHCb’s computing resources.

Once optimal detector performance is assured, the alignment and calibration constants are propagated to HLT2, which is deployed on around 3700 computer servers. These machines perform the ultimate-quality reconstruction of the full detector and apply around 1500 different selections to further reduce the data volume by a factor 10. The exceptional quality of LHCb’s real-time reconstruction allows these selections to not only cherry-pick interesting events but also to compress the raw detector data into high-level physics objects in real-time. This all-software procedure, allows LHCb a tremendous flexibility to select both the most interesting events and the most interesting pieces of each event, thus making best use of its computing resources for the full diversity of its physics programme. In the end around 10 Gigabytes of data are permanently recorded each second and made available to physics analysts.
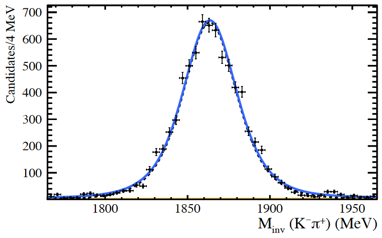
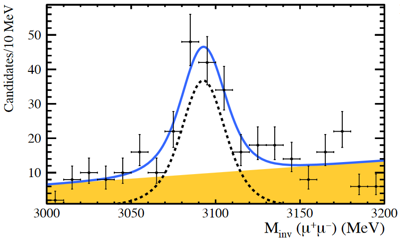
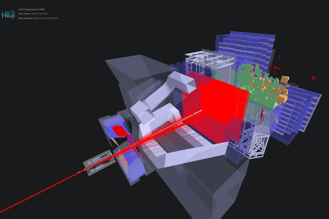
The event display images shown above were taken during the first Run 3 proton-proton collisions on July 5th (left) and the first lead-argon collisions on November 18 (right) using the new SMOG2 system, which allows LHCb to inject gas in the collision region and work in a fixed-target mode. The invariant mass peaks shown above, accumulated around the well known D0 and J/ψ masses, were reconstructed in HLT2, without offline processing.
The success of the Real-Time Analysis approach was only possible thanks to the extraordinary work of the online and subdetector teams during construction and commissioning of the new LHCb detector, which started to take data last year. The LHCb collaboration takes great pride in its growing diversity: within RTA many female and young physicists have been the driving force of the project since its creation and during commissioning. The software flexibility provided by the Data Processing and Analysis team allows physicists to access the data processed in real-time from anywhere in the world. Although some time will be needed to understand all the features of a brand new detector and data acquisition system, the large amount of data to be collected by LHCb during Run 3 will open the doors to unprecedented precision measurements and tests of the Standard Model of particle physics.
Read more in the CERN update.