
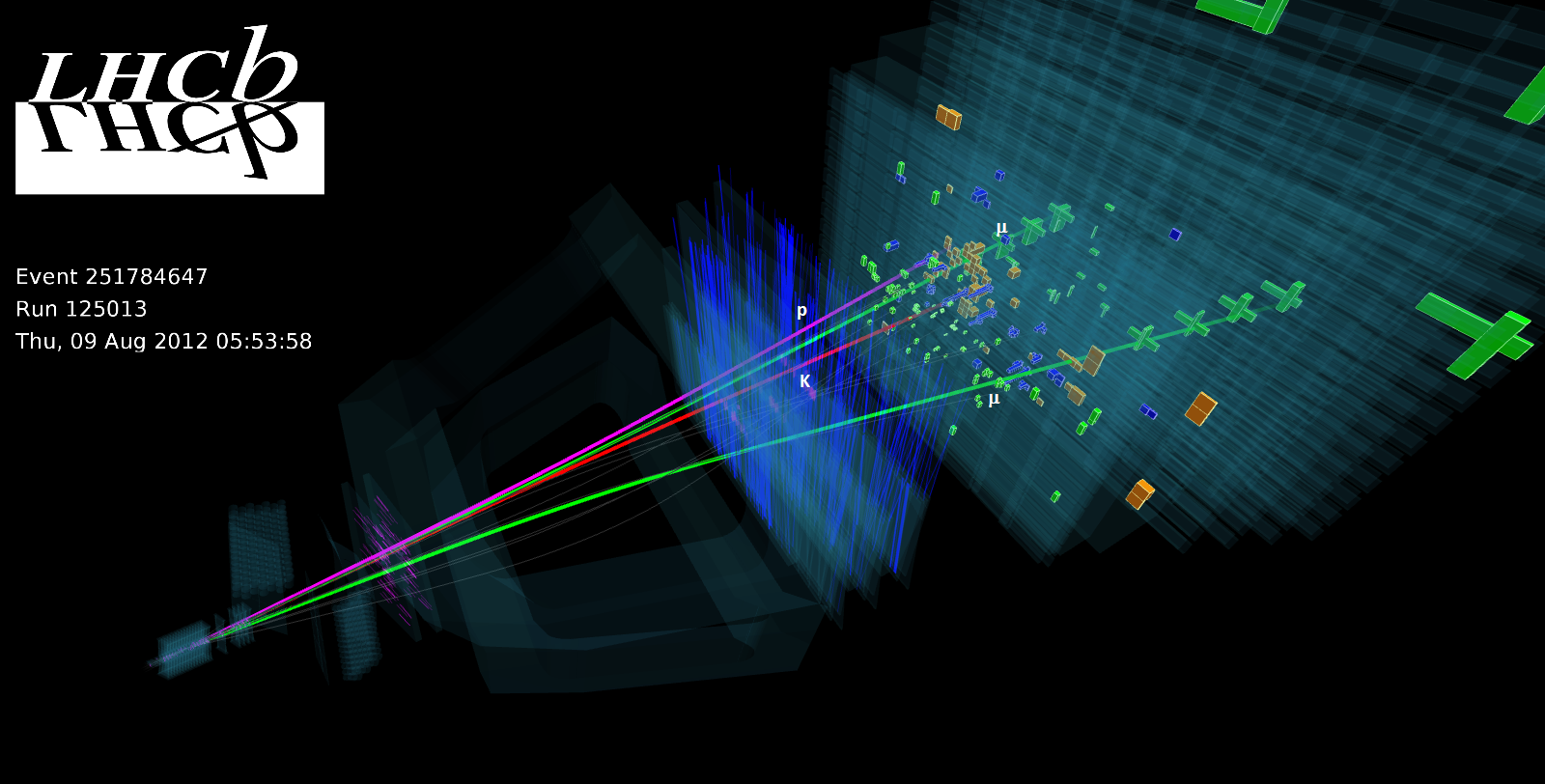
Today the LHCb collaboration complete the release of data collected throughout the Run I of the Large Hadron Collider at CERN. The sample made available amounts to approximately 800 terabytes (TB) of data. These data, collected by the LHCb experiment in 2011 and 2012, contain information obtained from proton-proton collisions[1] . The format made available provides pre-filtered data, suitable for a wide range of physics studies. The image below displays an event recorded during 2012.
All scientific results from the LHCb collaboration are already made publicly accessible in open-access papers. The numerical results from graphs are available in HEPData. Starting from today, not only are the results available, but also the data used by the researchers to produce these results are accessible. The data release is made within the framework of CERN’s Open Data Policy, which reflects values that have been enshrined in the CERN Convention for more than sixty years. LHCb data across runs I and II have been used for over 700 scientific publications including a number of significant discoveries, as described in previous LHCb public pages. Making these data available to the public allows research to be conducted by anyone in the world.
The collaboration has preprocessed the data by reconstructing experimental signatures, such as the trajectories of charged particles, from the raw information delivered by their complex detector system. The data are filtered, classified according to a large number of processes and decays, and made available in the same format as used internally by LHCb physicists. The data can be downloaded from the CERN Open Data portal.
To aid understanding, the samples come with extensive documentation and metadata, and a glossary explaining several hundred special terms used in the preprocessing. The data can be analyzed using dedicated LHCb algorithms, available as open-source software. We are pleased to make these data available for research, educational purposes, and non-profit applications. All data sets have digital identifiers (DOIs) for reference and citation. We welcome feedback on how our data are used and invite users to discuss and post questions in the CERN Open Data Forum.